最近想起来 libphpserialize 还有一个TODO,实现递归对象的序列化,顺手写写php序列化中"r"与"R"的意义
引用
引用到底是什么?是一个指针的语法糖么?是一个指针对象指向了另一个对象?更加
我们手里拿着一个数据的“引用”时,我们并没有在拿这个数据本身。
听起来非常的指针。其实不然,指针没有这么抽象,指针存在于C语言中,它存在的意义并没有这么抽象。我们平时说指针“指向了一个对象”实际上是我们自己不知不觉间对其进行了更高层级的抽象,让它“成为了”我们脑海中对另一个对象的引用。实际上没这么复杂,它本初存在的意义就是为了存一个地址。
像我们常用的Python,Java等直接操作引用的语言,将我们的对象全部藏了起来,给到我们手里的全部都是引用。当我们对这些对象进行操作的时候神の手(Kami no te)帮我们进行了一次解引用,再对对象进行了一系列操作。
理解了这一点,我们就能轻松地理解PHP序列化字符串中R与r的区别。
prologue
既然打了 php-src 的tag,就引用一下源码8
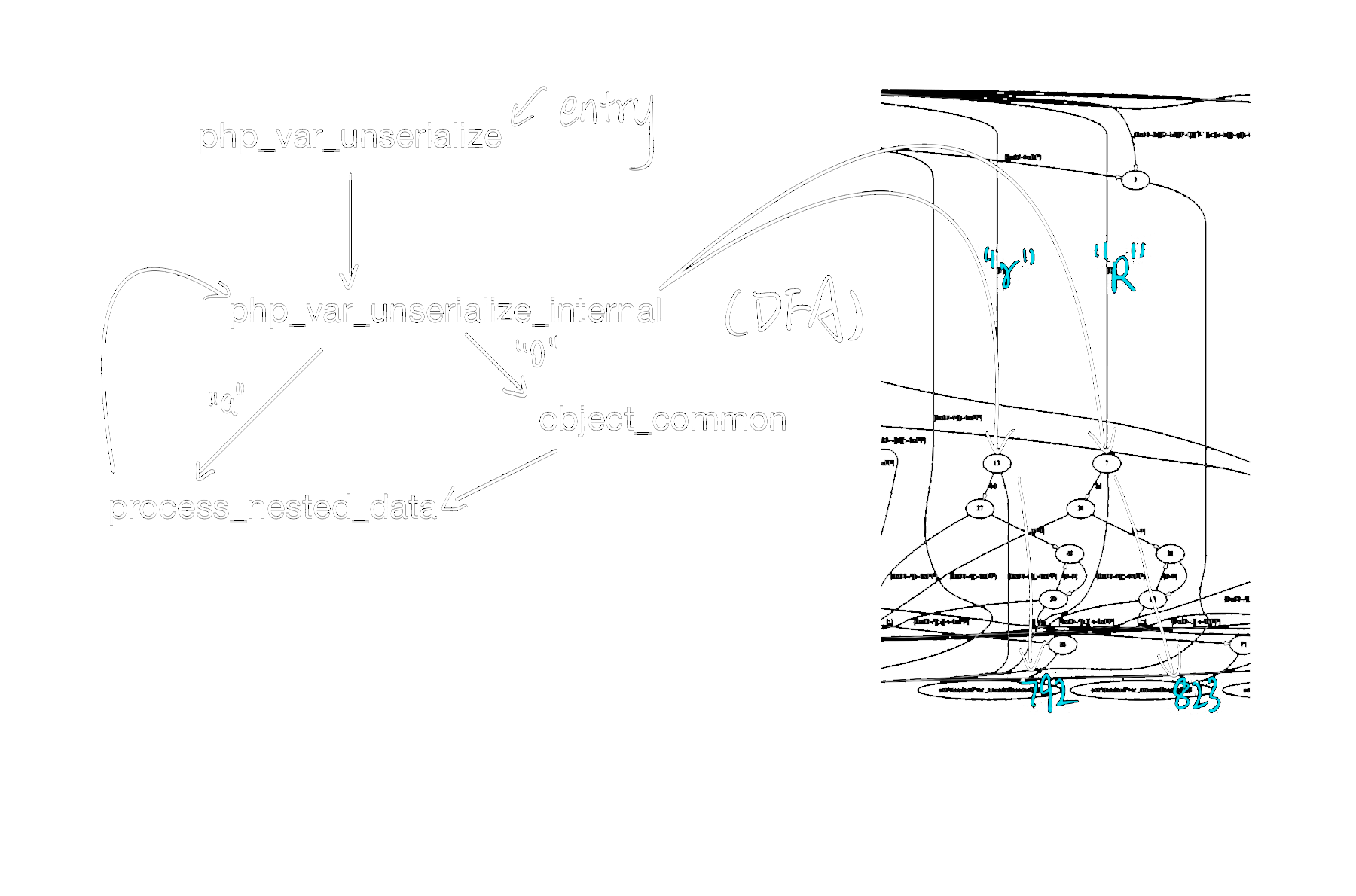
在php中,反序列化的实现主要存在与 ext/standard/var_unserializer.re 中。建议先打开这个文件放到一边再往下看。re2c 进行了代码生成。确定 有限状态自动机,以供编译。这样能够实现 类似
我们先对php中反序列化的流程大致熟悉一下,标蓝色的地方是处理R与r的code block行数(php 7.4.6)re2c -D -8 ext/standard/var_unserializer.re | dot -Tpng -o output.png
下文中都会以反序列化的代码来说明问题。看完了反序列化的代码再看序列化(ext/standard/var.c)会发现其实它们的结构逻辑都是非常类似的。博客里就不多说了。
R与r
当两个对象本来就是同一个对象时后出现的对象将会以小写r表示。
为什么?(看完“分析”以后再看这里)
.var_hash->last么?var_push作用类似的函数长这样
1 2 3 4 5 6 7 8 static inline zend_long php_add_var_hash (php_serialize_data_t data, zval *var) ... if (!is_ref && Z_TYPE_P (var) != IS_OBJECT) { return 0 ; } ... if ( existed ) return index; else add_new && return 0 ; }
其中判断了对象IS_OBJECT,而zval常规类型有下列几种:
1 2 3 4 5 6 7 8 9 10 11 IS_UNDEF IS_NULL IS_FALSE IS_TRUE IS_LONG IS_DOUBLE IS_STRING IS_ARRAY IS_OBJECT IS_RESOURCE IS_REFERENCE
1 2 3 4 5 6 7 8 9 10 11 12 <?php $x = new stdClass ;$x ->a = 1 ; $x ->b = $x ->a;echo serialize ($x );$y = new stdClass ;$x ->a = $y ; $x ->b = $y ;echo serialize ($x );$x ->a = $x ; $x ->b = $x ;
而当PHP中的一个对象如果是对另一对象显式的引用 ,那么在同时对它们进行序列化时将通过大写R表示
1 2 3 4 5 6 <?php $x = new stdClass ;$x ->a = 1 ;$x ->b = &$x ->a;echo serialize ($x );
分析
R与r的不同处理
对于“同一个对象”,php直接对取出的对象引用进行了一次解引用,便将这个 对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 "r:" uiv ";" { zend_long id; *p = YYCURSOR; if (!var_hash) return 0 ; id = parse_uiv (start + 2 ) - 1 ; if (id == -1 || (rval_ref = var_access (var_hash, id)) == NULL ) { return 0 ; } if (rval_ref == rval) { return 0 ; } ZVAL_DEREF (rval_ref); if (Z_TYPE_P (rval_ref) != IS_OBJECT) { return 0 ; } ZVAL_COPY (rval, rval_ref); return 1 ; }
而对于“对象引用”,其反序列化过程与上面小r非常像,不一样的地方在于 r begin 和 r end 之间:
php并没有对取出的引用进行解引用,直接将这个 引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (id == -1 || (rval_ref = var_access (var_hash, id)) == NULL ) { return 0 ; }if (Z_ISUNDEF_P (rval_ref) || (Z_ISREF_P (rval_ref) && Z_ISUNDEF_P (Z_REFVAL_P (rval_ref)))) { return 0 ; }if (!Z_ISREF_P (rval_ref)) { zend_property_info *info = NULL ; if ((*var_hash)->ref_props) { info = zend_hash_index_find_ptr ((*var_hash)->ref_props, (zend_uintptr_t )rval_ref); } ZVAL_NEW_REF (rval_ref, rval_ref); if (info) { ZEND_REF_ADD_TYPE_SOURCE (Z_REF_P (rval_ref), info); } } ZVAL_COPY (rval, rval_ref);
数字
那么,R/r后面跟的数字是怎么决定的呢?首先我们先来“黑箱分析”一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <?php $x = array (new stdClass );$x [1 ] = &$x [0 ];echo serialize ($x );var_dump (unserialize ('a:2:{i:0;O:8:"stdClass":0:{}i:1;R:1;}' ));$x = new stdClass ;$x ->a = 1 ;$x ->b = &$x ->a;echo serialize ($x );var_dump (unserialize ('O:8:"stdClass":2:{s:1:"a";i:1;s:1:"b";R:1;} ' ));
相信大家定睛看两眼上面的例子就能猜出,R/r后面的数字指代的是在 同一反序列化过程中
看过上面的源码以后很容易猜到,在反序列化过程中:
1 if (id == -1 || (rval_ref = var_access (var_hash, id)) == NULL ) { return 0 ; }
这一步正是上面取值的关键。在反序列化过程中我们看到 php_var_unserialize_internal 函数在一开头就进行了 var_push(var_hash, rval); 这样的操作(当然前提是反序列化的对象的标记不能是’R’,因为“引用”本身如果也计算在内,那么就有可能出现循环引用。浙恒河里),而 var_push 正是向列表 var_hash append一个新的元素。
其实 var_hash 并不单单是一个列表,只是本文为方便这么说罢了。
此处小重点
这时候就有同学要问了,数组的index是数字,对象的属性名是字符串,它们都存在于反序列化过程当中,为什么它们没有被append进 var_hash 呢?我们回头看一下 var_push 的条件:
1 if (var_hash && (*p)[0 ] != 'R' ) {
后面那个’R’已经在恒河里了,那么前面那个 var_hash 非 NULL 的判断意义何在呢?var_hash 是哪里来的呢?php_var_unserialize_internal 的参数里有个宏
1 2 3 4 5 #define UNSERIALIZE_PARAMETER \ zval *rval, const unsigned char **p, \ const unsigned char *max, \ php_unserialize_data_t *var_hash static int php_var_unserialize_internal (UNSERIALIZE_PARAMETER, int as_key)
任何看了源码的人看到这里都会<龙门粗口>,槽点实在是太多了
自然而然地,我们回去看这个internal是怎么调用的,看看什么情况下传入的 var_hash 为 NULL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 static int php_var_unserialize_internal (UNSERIALIZE_PARAMETER, int as_key) if match "a:<arr_len>" { ... process_nested_data (UNSERIALIZE_PASSTHRU, ...); ... } if match "O:<type>:<cnt_attrs>" { ... object_common (UNSERIALIZE_PASSTHRU, ...); ... } } static inline int object_common (UNSERIALIZE_PARAMETER, zend_long elements, zend_bool has_unserialize) ... process_nested_data (UNSERIALIZE_PASSTHRU, ...); ... } static zend_always_inline int process_nested_data (UNSERIALIZE_PARAMETER, HashTable *ht, zend_long elements, zend_object *obj) while (elements-- > 0 ) { zval key, *data; zend_property_info *info = NULL ; php_var_unserialize_internal (&key, p, max, NULL , 1 ); if (obj) { } php_var_unserialize_internal (data, p, max, var_hash, 0 ); if (info) { zend_ref_add_type_source (Z_REF_P (data), info); } } }
可以看到,当反序列化数组、对象这种东西的时候,只有反序列化 值 var_hash 这个列表, 键
有趣的事情
1
1 2 3 4 $x = array (new stdClass );$x [1 ] = &$x ;echo serialize ($x );
这就是序列化部分的事情了。可是今天实在不想写了。
2
C++的引用实际上并不一定占用堆栈空间。对对象的解引用很有可能 是在编译期间完成的。
求Star
建议去点个star,

 !!!
!!!